完整部署实践
本文按照单实例的模式部署来实践,所有的服务都是单实例的模式运行
Prometheus
版本:2.40.1 操作系统:Darwin
下载
配置
cd prometheus-2.40.1.darwin-arm64
- prometheus.yml 主配置文件
- first_rules.yml 告警规则配置文件
- instances.yml 监控对象配置文件
主配置文件
Prometheus 主配置文件
global:
scrape_interval: 15s
evaluation_interval: 10s
scrape_timeout: 10s
external_labels:
monitor: "local"
# 告警alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
# 告警规则文件
rule_files:
- first_rules.yml
# 抓取任务配置
scrape_configs:
- file_sd_configs:
- files:
- instances.yml
refresh_interval: 10s
job_name: basic
metrics_path: /metrics
scheme: http
scrape_interval: 15s
scrape_timeout: 10s
告警规则配置
全局的告警规则配置文件 first_rules.yml
groups:
- name: GlobalAlertRules
rules:
- alert: InstanceDown
expr: up{job="basic"} == 0
for: 20s
labels:
level: crit
annotations:
summary: "Instance {{ $labels._name }} down"
description: "Instance {{ $labels._ip }} down"
监控对象配置
监控对象的配置文件 instances.yml
# 本地的node exporte
- labels:
_ip: 127.0.0.1
_name: node_expoter_01
_endpoint: node_expoter_01
_product_name: devops
targets:
- 127.0.0.1:9100
# 本地的Prometheus
- labels:
_ip: 127.0.0.1
_name: prometheus_local
_endpoint: prometheus_local
_product_name: devops
targets:
- 127.0.0.1:9090
# 假的测试实例
- labels:
_ip: 10.10.10.10
_name: node_expoter_02
_endpoint: node_expoter_02
_product_name: devops
targets:
- 10.10.10.10:9100
检查配置文件
cd prometheus-2.40.1.darwin-arm64
./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 1 rule files found
SUCCESS: prometheus.yml is valid prometheus config file syntax
Checking first_rules.yml
SUCCESS: 1 rules found
启动服务
cd prometheus-2.40.1.darwin-arm64
./prometheus --config.file="prometheus.yml" --web.listen-address="0.0.0.0:9090" --web.enable-lifecycle
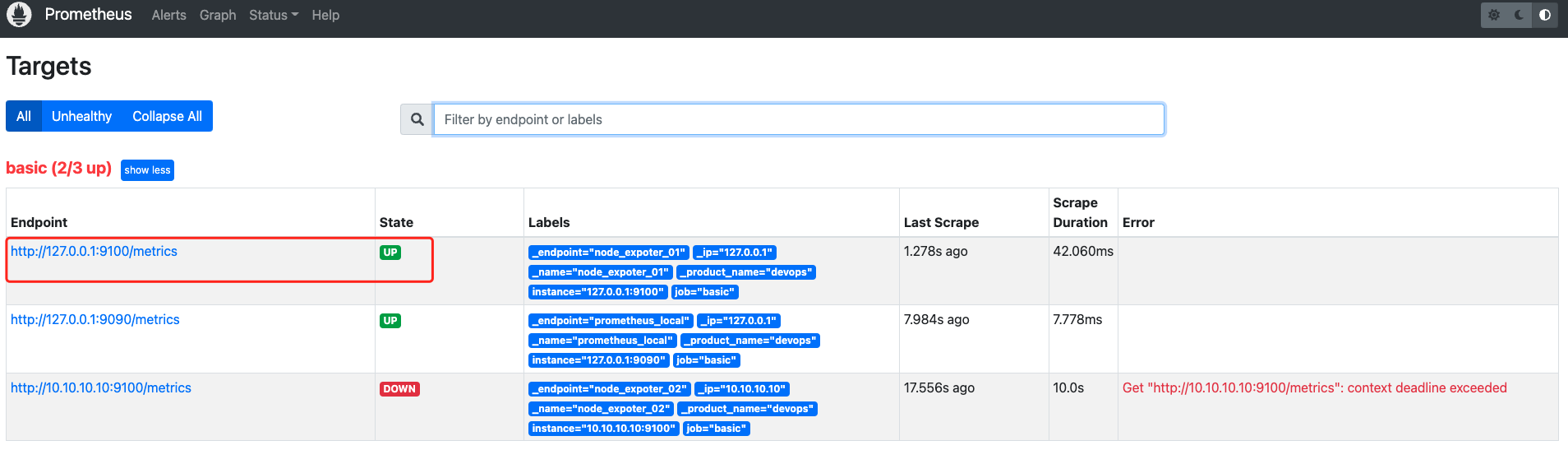
启动完 Prometheus 服务之后,此时在 Prometheus UI 中查看 targets,会发现只有本地的 Prometheus 服务监控正常,其他两个,一个是我们真实的 node exporter 服务(接下来需要配置的),一个是假的测试监控对象
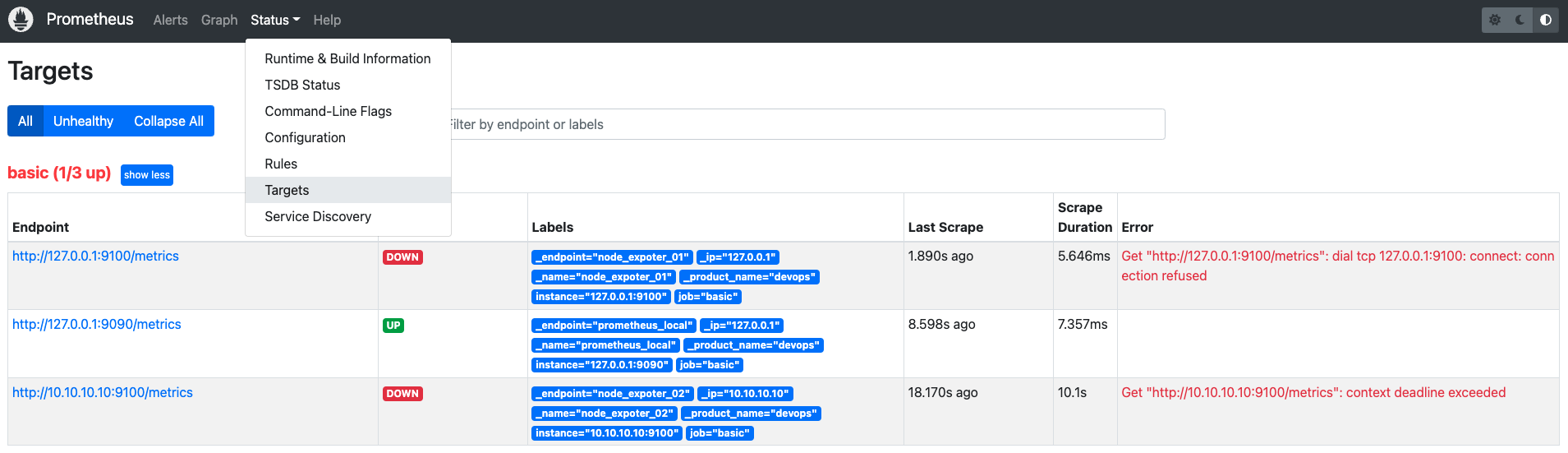
在 Prometheus UI 中查看 alerts,目前告警的如图
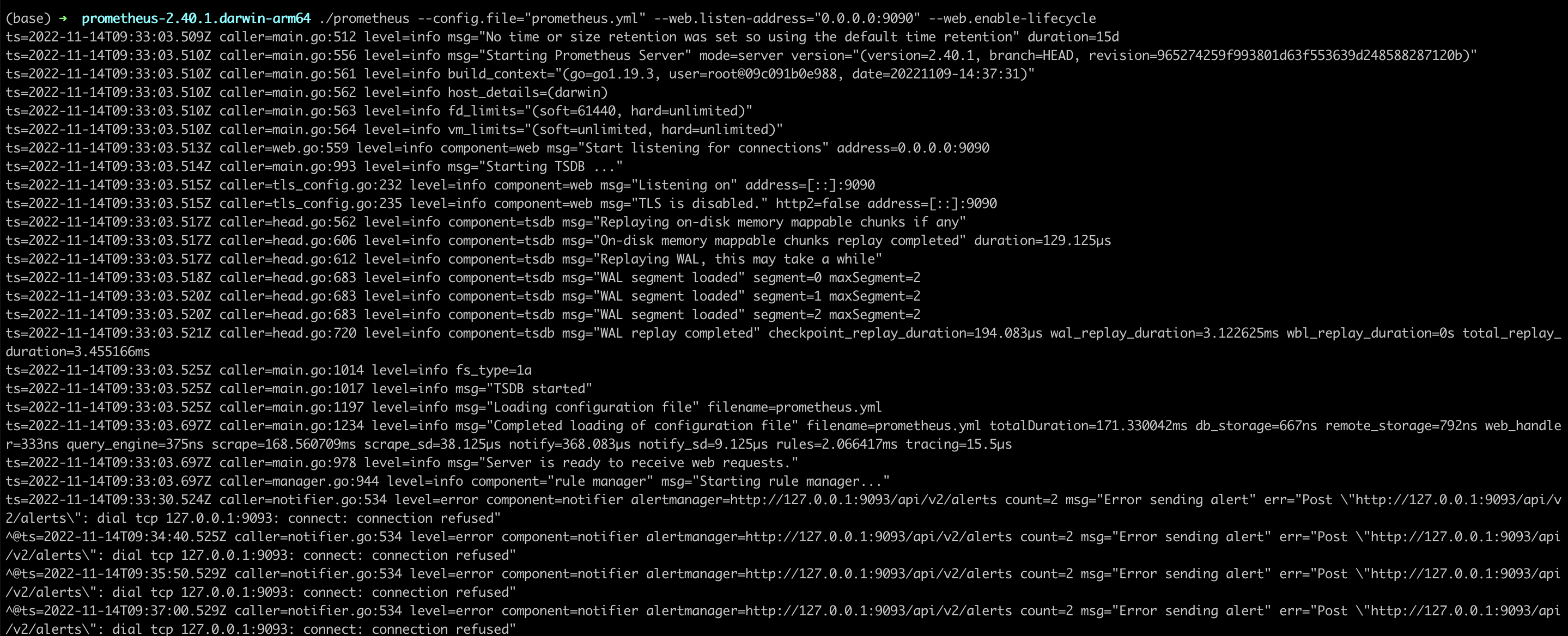
此时因为 Alertmanager 还没有配置,Prometheus 服务报错如下,接下来我们配置 Alertmanager
Alertmanager
版本:0.24.0 操作系统:Darwin
下载
配置
cd alertmanager-0.23.0.darwin-arm64
- alertmanager.yml 主配置文件
Alertmanager 主配置文件
global:
resolve_timeout: 5m
route:
group_by: ["alertname", "level", "_product_name"]
group_wait: 30s
group_interval: 1m
repeat_interval: 10s # 为了方便测试,我们配置重复发送告警的时间很短
receiver: "devops"
receivers:
- name: "devops"
webhook_configs:
- url: "http://127.0.0.1:5001/alerts"
inhibit_rules:
- source_match:
severity: "crit"
target_match:
severity: "warn"
equal: ["alertname", "level", "_product_name"]
检查配置文件
cd alertmanager-0.23.0.darwin-arm64
./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:
- global config
- route
- 1 inhibit rules
- 1 receivers
- 0 templates
启动服务
cd alertmanager-0.23.0.darwin-arm64
./alertmanager --config.file="alertmanager.yml" --web.listen-address="127.0.0.1:9093"
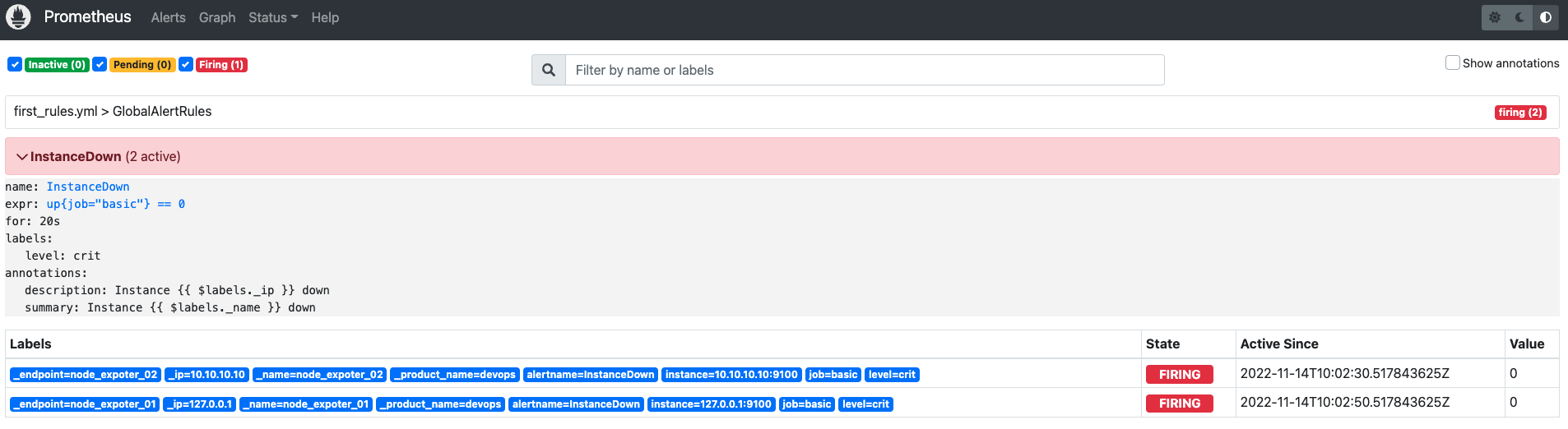
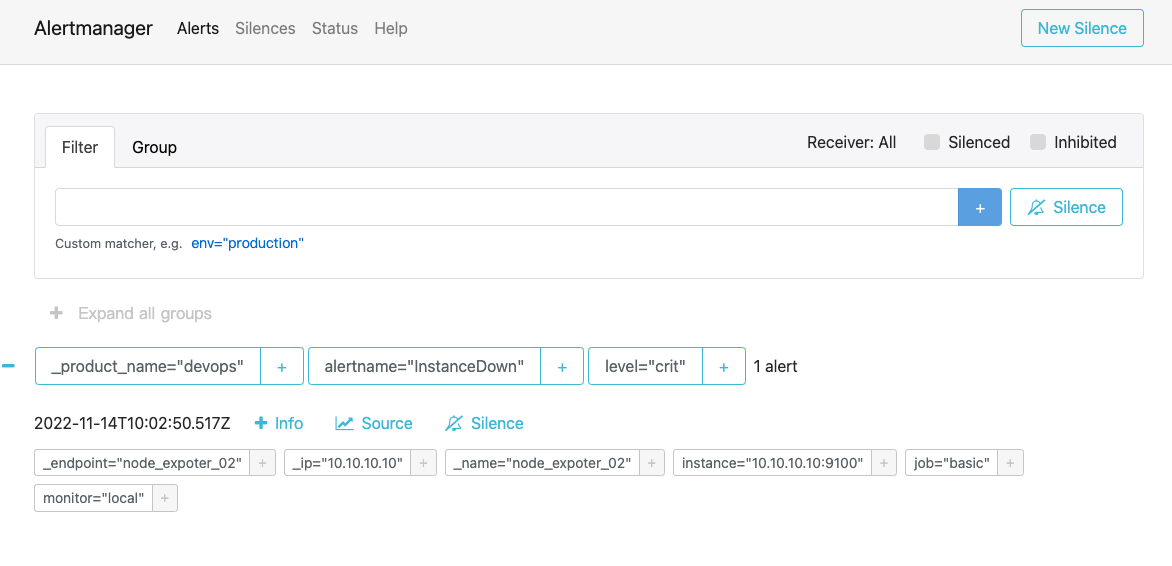
当 Alertmanager 服务启动完之后,等待几分钟,此时看到 Alertmanager 中的告警如图,就是 Prometheus 的告警发送到了 Alertmanager
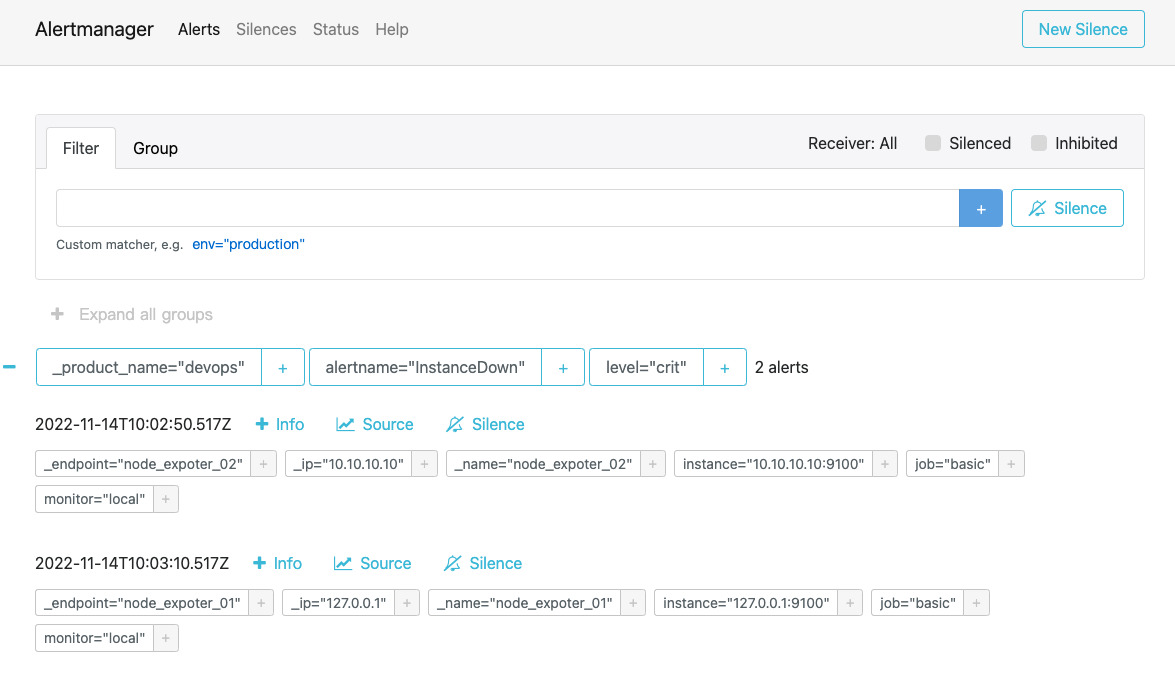
发送告警
根据上述的 Alertmanager 的配置文件,我们的 Webhook 服务还没有,所以暂时还发送不了告警信息给用户,接下来我们简单开发一个 Webhook 服务来来看下目前正在告警的信息发送出来的示例,我们的 webhook 服务默认将信息打印在标准输出中
Webhook 服务
运行服务:go run main.go
package main
import (
"encoding/json"
"fmt"
"log"
"net/http"
"time"
)
type AlertMsg struct {
Receiver string
Status string
GroupLabels map[string]string
CommonLabels map[string]string
CommonAnnotations map[string]string
ExternalURL string
Alerts []Alert
}
type Alert struct {
Status string
Labels map[string]string
Annotations map[string]string
StartsAt time.Time
EndsAt time.Time
GeneratorURL string
Fingerprint string
}
func main() {
http.HandleFunc("/alerts", alertHandler)
log.Fatal(http.ListenAndServe("0.0.0.0:5001", nil))
}
func alertHandler(w http.ResponseWriter, r *http.Request) {
dec := json.NewDecoder(r.Body)
defer r.Body.Close()
var m AlertMsg
if err := dec.Decode(&m); err != nil {
log.Printf("decoding alert message error: %v", err)
return
}
content, _ := json.MarshalIndent(m, "", " ")
fmt.Println(string(content))
}
此时稍等片刻,我们看到 Alertmanager 发送的告警信息(发送给了我们的 webhook 服务)如下
{
"Receiver": "devops",
"Status": "firing",
"GroupLabels": {
"_product_name": "devops",
"alertname": "InstanceDown",
"level": "crit"
},
"CommonLabels": {
"_endpoint": "node_expoter_02",
"_ip": "10.10.10.10",
"_name": "node_expoter_02",
"_product_name": "devops",
"alertname": "InstanceDown",
"instance": "10.10.10.10:9100",
"job": "basic",
"level": "crit",
"monitor": "local"
},
"CommonAnnotations": {
"description": "Instance 10.10.10.10 down",
"summary": "Instance node_expoter_02 down"
},
"ExternalURL": "http://local:9093",
"Alerts": [
{
"Status": "firing",
"Labels": {
"_endpoint": "node_expoter_02",
"_ip": "10.10.10.10",
"_name": "node_expoter_02",
"_product_name": "devops",
"alertname": "InstanceDown",
"instance": "10.10.10.10:9100",
"job": "basic",
"level": "crit",
"monitor": "local"
},
"Annotations": {
"description": "Instance 10.10.10.10 down",
"summary": "Instance node_expoter_02 down"
},
"StartsAt": "2022-11-15T01:58:10.517Z",
"EndsAt": "0001-01-01T00:00:00Z",
"GeneratorURL": "http://local:9090/graph?g0.expr=up%7Bjob%3D%22basic%22%7D+%3D%3D+0\u0026g0.tab=1",
"Fingerprint": "e9dac55f7d8a4e79"
}
]
}
发送飞书告警
如果需要发送飞书告警,首先需要在你的某个飞书聊天群中中新建一个飞书机器人,拿到机器人的 webhook 地址。我们还需要将上述的 webhook 服务再次封装下,将告警信息发送给飞书的 webhook 机器人。具体实践请看 告警信息发送实践
NodeExporter
版本:1.4.0 操作系统:Darwin,我们原打算使用这个版本,但是发现这个版本在 Darwin 中启动不了,所以我们采取 docker 的方式启动
启动
docker pull prom/node-exporter
docker run -d --name=node_exporter -p 9100:9100 prom/node-exporter:latest
当我们启动了一个本地的 node exporte 服务之后,由于这个 node exporter 监控实例已经在 Prometheus 的 target 中,所以在 Prometheus 中,这个实例很快(一个抓取周期)就会显示 Up,如图
同时在 Alertmanager 中,原先的关于这个实例的告警就会消失,如图只剩下另外一个测试实例
Grafana
为了查看监控实例的仪表盘信息,我们直接通过 brew 安装 Grafana,并且不做配置文件配置,按照默认方式直接启动服务
安装启动
brew install grafana
brew services start grafana
配置
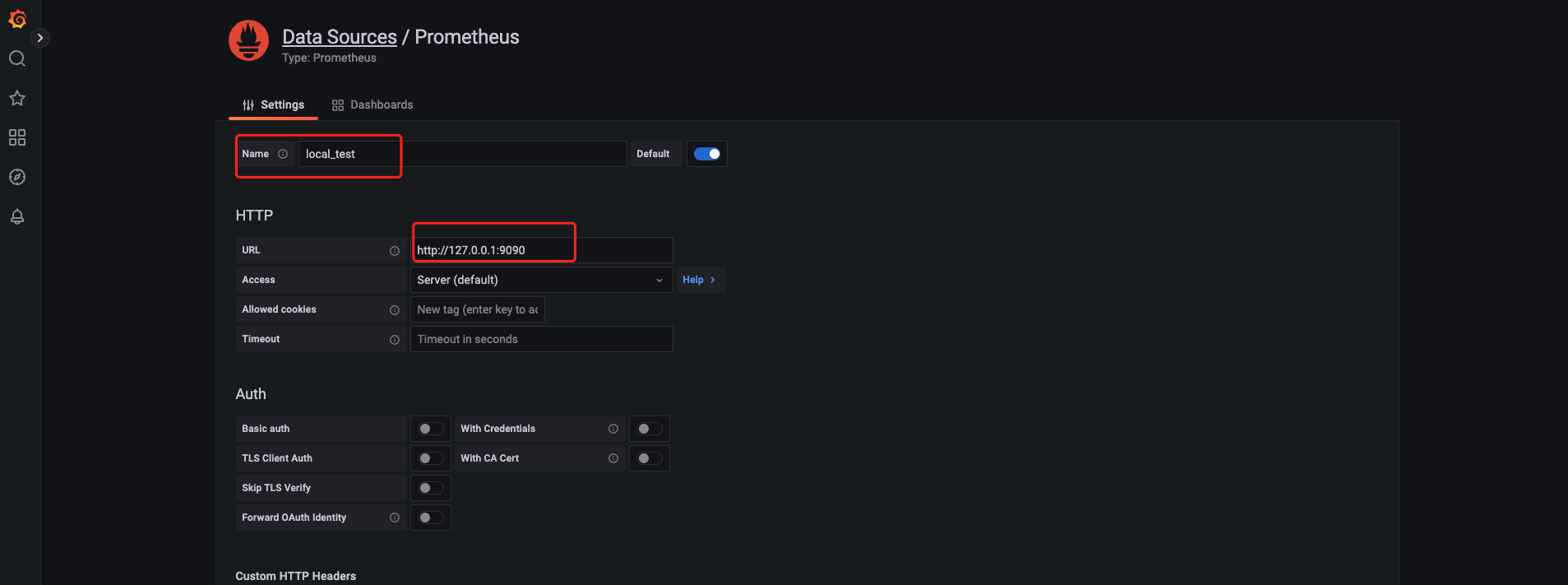
Datasource
配置数据源,也就是本地的 Prometheus 服务
Dashboards
导入 Dashboard,我们采用官方的 1 Node Exporter for Prometheus Dashboard EN 20201010
初次导入之后监控对象的仪表盘信息如图,如果需要本地化,那么我们需要在 Dashboard 的配置中,修改变量,在仪表盘中也相应修改 PromQL 语句
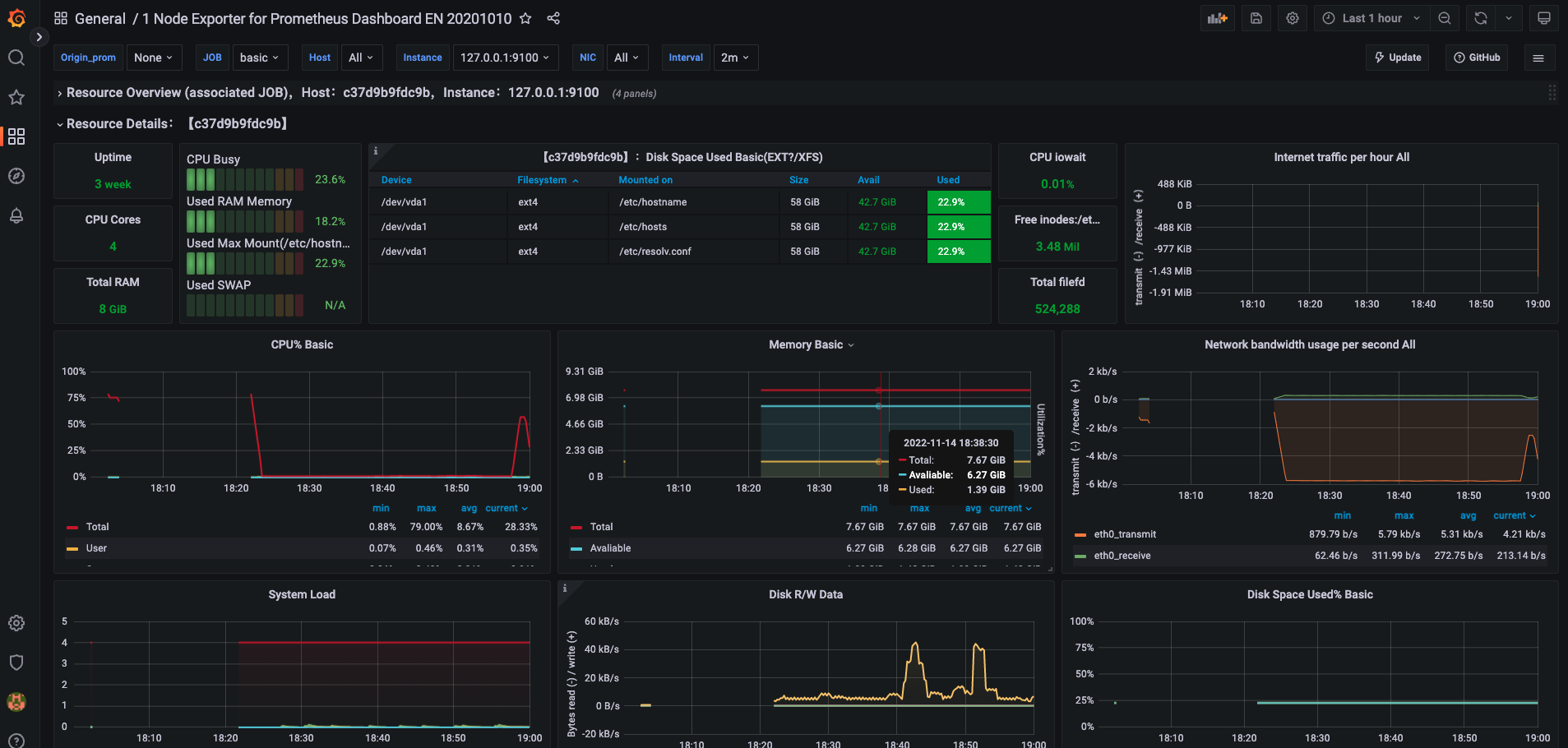
结语
至此,我们将 Prometheus+Alertmanager+NodeExporter+Grafana 都配置了一遍,可以大致了解到 Prometheus 这一套监控体系是怎么运作的了。